The things we see online and the ones that prosper online have elbowed their way into our consciousness and if they are useful and satisfy needs can survive. Most do not. Only the very fittest can make it.
An influential tradition in media research is referred to as 'use and gratifications'. This approach focuses on why people use particular media rather than on content. In contrast to the concern of the 'media effects' tradition with 'what media do to people' (which assumes a homogeneous mass audience and a 'hypodermic' view of media), use and gratification can be seen as part of a broader trend amongst media researchers which is more concerned with 'what people do with media', allowing for a variety of responses and interpretations. Some commentators have argued that gratifications could also be seen as effects: e.g. thrillers are likely to generate very similar responses amongst most viewers. And who could say that they never watch more TV than they had intended to? Watching TV helps to shape audience needs and expectations.
Use and Gratification theory is old but in the 40 years since the most recent manifestation was explicated, social media has brought it to the fore again. It presents the use of media in terms of the gratification of social or psychological needs of the individual (Blumler & Katz 1974). The mass media compete with other sources of gratification, but gratifications can be obtained from a medium's content (e.g. watching a specific programme), from familiarity with a genre within the medium (e.g. watching soap operas), from general exposure to the medium (e.g. watching TV), and from the social context in which it is used (e.g. watching TV with the family).
Theorists argue that people's needs influence how they use and respond to a medium. Zillmann (cited by McQuail 1987: 236) showed the influence of mood on media choice: boredom encourages the choice of exciting content and stress encourages a choice of relaxing content. The same TV programme may gratify different needs for different individuals. Different needs are associated with individual personalities, stages of maturation, backgrounds and social roles. Developmental factors seem to be related to some motives for purposeful viewing: e.g. Judith van Evra argues that young children may be particularly likely to watch TV in search of information and hence more susceptible to influence (Evra 1990: 177, 179). Translating these ideas into online and in particular social media is very attractive and with the research we have already (Amaral 2009) using semantics, has a lot of close similarities.
The internet is being created in the image of human interest, needs and desires. Tinkering with this driving force is dangerous. Some politicians believe they can, others in management try and governments fervently wish they could. But, as the Arab Spring showed, switching off the internet is far too difficult when living with the consequences.
This evolutionary development of the internet has made it very robust.
So many people have tried to prevent this evolution in the past that it has considerable and hugely complex defensive capabilities.
The UN agency was updating its International Telecommunication Regulations (ITRs) at the World Conference on International Telecommunications (WCIT) in Dubai in December 2012, but some member states feared it would lead to centralised control of the internet by the UN.
A wide range of organisations and academics raised even deeper concerns about the plans to seek to establish for the first time ITU dominion over important functions of multi-stakeholder internet governance entities, such as the Internet Corporation for Assigned Names and Numbers (Icann).
For many the WCIT threatened the "free and open internet". It caused a furore, largely because no one really knew what the outcome would be. It had the potential outcome ranging from tinkering at the edges to the potential global disruption of communication as we know it.
The ability to move from mere digital interaction to analog and physical interaction using the internet as a semi intelligent platform or channel is now adding a lot to the way we live.
It is offering a lot to the practice of PR and a wider range of semiotic markers that can be used in the practice of public relations.
The mobile phone app that controls a camera using bluetooth or wifi connectivity is an adjunct to a visual PR tactic that can be applied at any product launch by an intern. Furthermore, a photograph taken in this way can be uploaded automatically to a photo sharing site or other cloud based facility without a human hand in sight. Such is the digital real time press pack and the idea is not new.
The Google Driverless Car is a significant step further and between these two extremes lies a wide range of PR PR tactics.
We are already aware that semiotic PR is being practiced. Almost by accident, it has crept up on the profession. It is now commonplace for a Public Relations programme to be multi media.
The PR industry has strayed into the semiotic web as a discipline for affective relationship intervention. As a result, it faces the new realities of the complexity of semiotics (as opposed to media -including social media - based PR) and the precept of PR using the perspective of constituents and their affective technologies.
Google offers a semantic capability. It shows us how semantics has entered into the relationships we have in the media and between ourselves. Semantics can add values atsuch as the type of media, date and even country. These added elements are semiotic and can be technically as well as user created.
We also know that this information is passed along between one person and another and often shared with a wider community.
The drivers for building, creating and optimising the efficacy of online communities has been the subject of considerable research.
A very detailed study by Matthew Rowe, Miriam Fernandez, Sofia Angeletou, and Harith Alani showed that, in online communities, users interact with one another around a shared topic or interest and exhibit behaviour that can be used to label them with their roles in the community. By deriving the role composition of a community - i.e. the percentage distribution of different roles - the composition can be associated with signifiers of health, such as activity, and used to identify what worked for the community and what did not.
For public relations, this means that practitioners can become more effective when they use such signifiers.
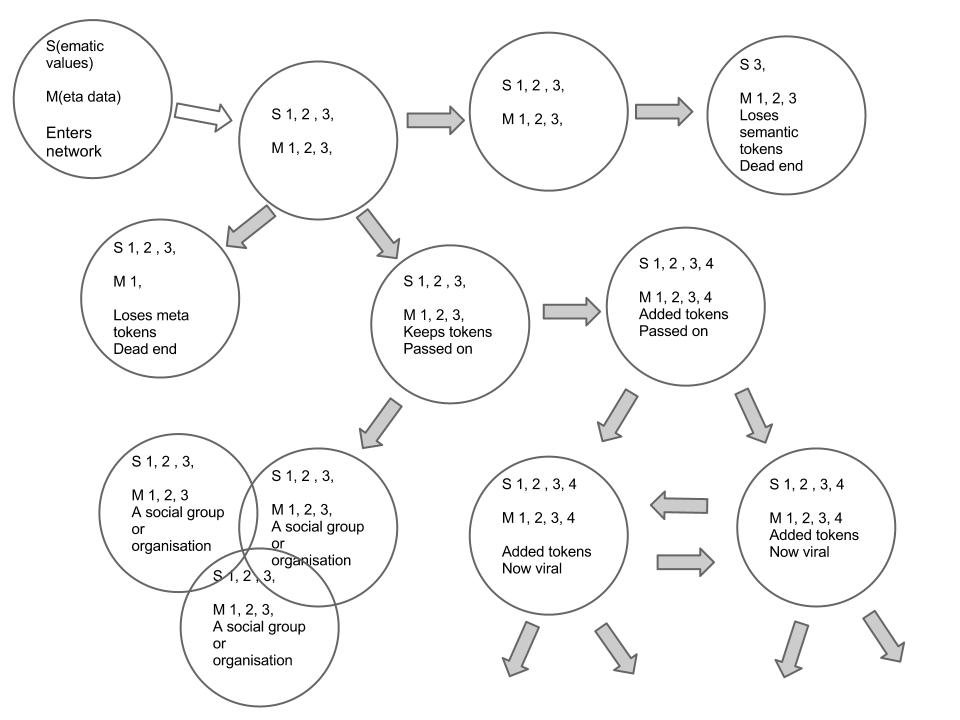
This is becoming the norm for much social interaction. It is network communication. Citations, such as tweets, Facebook, LinkedIn and G+ content, blog post or web pages even emails and SMS messages, carry a lot of information much of this is part of the structure of content and media and is called meta data.
As citations are exposed on line they are automatically available through a lot of protocols and so enter the network. Networks have intersections where a citation becomes available to be found by search engines, lists and channels like Facebook, Google+, Twitter and many many more.
We find that at each intersection of the network values are shared. Each citation carries with it a lot of information. These data are significant and contribute value. They are values. Some of these values are about the media. Is it Twitter, a newspaper, Facebook or a blog? This kind of information is passed on by the software in use. It could also be that some of the content comes in the form of other tags such as Facebook 'Likes' or Google +'s.
Research shows that a) users' motivation for tagging varies not only across, but also within tagging systems, and that b) tag agreement among users who are motivated by categorizing resources is significantly lower than among users who are motivated by describing resources. Such fndings are relevant for 1) the development of tag-based user interfaces (even in public fora such as Twitter, Facebook and Google+) 2) the analysis of tag semantics and 3) the design of search algorithms for social tagging systems.
These are the additional semiotic elements in addition to the semantic concepts inherent in the text.
Of course, all web pages (and each Tweet and Instagram picture is a web page) has meta data.
Historically, as Aaron Bradley at Search Engine Land reports, meaning has been given to pieces of text on the Internet by use of the ‘meta’ tag, short for ‘metadata’. Metadata is a word that can be defined as contextual information about a piece of content, such as an individual page on a website.
An older example of metadata would be a library’s card catalogue – at least if you can remember back to the delightfully primitive days before computerized databases were installed in libraries. Each card in those drawers represents a book that exists within the library, and has the name of the book, the author, the subject, and the Dewey decimal system subject category number.
The card for a book is not the book itself, but it describes the book in a way that it can be found – the information on the card gave the book a meaning that could be understood by the ‘process’ or ‘mechanism’ of finding a book using the card catalogue.
The meaning conveyed by the card catalogue, that allows one to find a book in a library, is only an identifier for a book – that description is not necessarily included in the contents of the book itself.
In a similar manner, meta tags have been used to give a webpage a meaning that could be ‘understood’ and acted upon by a process or mechanism depending on the nature of that meaning.
The words or their meaning in the meta data do not affect or appear in the content that they describe – they merely describe the content just enough to help them be handled by a process that, like the library card catalogue, most often involves finding that content.
Meta tags were originally used in the form of HTML elements with attributes like ‘keywords’, ‘description’, and ‘author’.
The words used in those tags were not part of the human-visible content on the webpage they described, but they did assist search engine crawlers in describing them just enough to figure out whether or not they had anything to do with a user’s search query. In some cases, they still do.
Over the years, innovations have come about and progress has been made in finding ways to describe content in a better and more detailed manner. From ‘alt’ attributes describing what is depicted in a particular image, to XML, RDF, microformats, Dublin Core metadata, and HTML5, these descriptions of content are becoming more and more detailed, and consequently more and more useful to browsers and the technical community.
In 2012 Google announced e-commerce meta tags from the GoodRelations project have been integrated into schema.org. This vastly increases the number of schema.org classes and properties available for e-commerce websites. It is worth keeping an eye on such developments for the opportunities it offers for PR. In this instance fashion PR will find that campaigns using the GoodRelations project syntax will get to target constituents more and in a richer format.
Each of these elements describe the citation and help in its distribution. To get some idea of how these elements can be used metadata search engines are useful. An example of how metadata can affect search results is shown using http://harvester.kit.edu. It provides some examples of different findings using different tags ( a list of meta search engines is available from Wikipedia http://en.wikipedia.org/wiki/List_of_search_engines#Metasearch_engines).
As each citation passes through the network there is a form of ‘negotiation’ that takes place as to whether the citation is accepted by a potential recipient or not. A blog post will not be accepted by Twitter but a short sentence and URL might be. The technology looks at the signs to identify whether the citation will be accepted.
In addition, there is a human element. Has the person set up their online presence to accept the citation (for example have they signed up for a social media channel of not)? Is this the right time of day for the person to be receptive to messages (perhaps the citation was published in a different time zone)? Are these the messages that the person wants to see or have they set up barriers to stop the content getting through.
The next part of the process is whether the citation prompt the recipient to do something? Doing something will, of course, also affect the message. It will add a tag, a semiotic marker, showing that the software or person has shared the content including the semantic and semiotic content.
Sometimes the person will edit or add to the content adding or taking away values associated with the message. The nature of networked communication is that as it passes through the network it is changed.
This is one of the big changes in Public Relations. Practitioners are now moving from linear, informational, communications to networked communication. The nature of online public relations is that any control that a practitioner may have had in other times have now evaporated. The internet is the arbeter.
As we will see, network communication can be very powerful, even viral in nature.
Although few communication theorist would still accept it, the informational approach has been a most influential model of communication. It reflects a common sense (if misleading) understanding of what communication is.
Shannon and Weaver's original model consisted of five elements:
- An information source, which produces a message (Keith Urbahn)
- A transmitter, which encodes the message into signals (Twitter)
- A channel, to which signals are adapted for transmission (the Internet)
- A receiver, which 'decodes' (reconstructs) the message from the signal (Twitter, email, Tweetdeck etc)
- A destination, where the message arrives (laptop, smartphone etc)
A sixth element, noise is a dysfunctional factor: any interference with the message travelling along the channel (such as 'static' on the telephone or radio) which may lead to the signal received being different from that sent.
Lasswell's verbal version of this model: 'Who says what in which channel to whom with what effect ?' was reflected in subsequent research in human communication which was closely allied to behaviouristic approaches.
In the networked model, which is closer to conversations held in a community or group, a richer transaction takes place. The internet offers extra semiotic content that can be equated to body language in face to face communication.
In the networked communications model, meaning can be passed on without much by way of change other than it is associated with a technology or a person adding the endorsement inferred by passing the values to a third party or many third parties in a group or network.
Alternatively, the meaning may be changed by adding or taking away semantic or semiotic values or tags (an activity that can be done by human or technical agents) .
The circumstance of the author may change the way a social media is used and is seen in how people used Twitter after the Great East Japan Earthquake. First, we gathered tweets immediately after the earthquake and analyzed various factors, including locations. The results revealed two findings: (1) people in the disaster area tend to directly communicate with each other (reply-based tweet). On the other hand,(2) people in the other area prefer spread the information from the disaster area by using Re-tweet.
The combination of network communication and semantics is shown to outperform other forms of communication and information distribution in many cases.
We know, from the research of Bruno Amaral, that when people have common values, they tend to cluster together online. Such clustering is found as common aims and values of organisations and in movements on and off line. Other research in different media contribute to this thinking including Twitter where we find semantic tags are influential. The nature of semantic cues in facebook also support this hypothesis. The use of tags or signifieres is is a common practice and adds to the values associated with the content. There is a significant effect from the post /content type and category on likes and comments as well as on interaction duration. The posting day has an (limited) effect too.
As values are added without degradation of values extant (existing semiotic tokens) a viral phenomenon occurs.
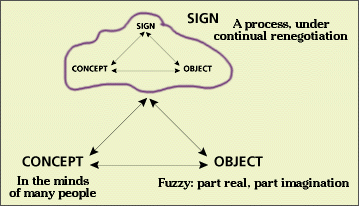
Perhaps one can reflect on the two models with the contributions of Daniel Chandler who writes:
“As Reddy (Reddy M 1979) notes, if this view of language were correct, learning would be effortless and accurate. The problem with this view of language is that learning is seen as passive, with the learner simply 'taking in' information (Bowers 1988: 42). I prefer to suggest that there is no information in language, in books or in any medium per se. If language and books do 'contain' something, this is only words rather than information. Information and meaning arises only in the process of listeners, readers or viewers actively making sense of what they hear or see. Meaning is not 'extracted', but constructed.
............
References
- Blumler J. G. & E. Katz (1974): The Uses of Mass Communication. Newbury Park, CA: Sage
- McQuail, Denis (1987): Mass Communication Theory: An Introduction (2nd edn.). London: Sage
- Evra, Judith van (1990): Television and Child Development. Hillsdale, NJ: Lawrence Erlbaum
- Brandt, P. Aa., Meaning and the machine: Toward a semiotics of interaction. In: P. Bøgh Andersen, B. Holmqvist & J. F. Jensen, eds., The Computer as Medium (Cambridge, Cambridge University Press, 1993) 128 - 140.
- Chandler D 2011 http://www.aber.ac.uk/media/Documents/short/trans.html accessed July 2011)
- UNDERSTANDING WHY USERS TAG: A SURVEY OF TAGGING MOTIVATION LITERATURE AND RESULTS FROM AN EMPIRICAL STUDY. Markus Strohmaier, Christian Körner, Roman Kern Journal of web Semntics Vol 17 (2012) http://www.websemanticsjournal.org/index.php/ps/article/view/318
- http://searchengineland.com/e-commerce-seo-using-schema-org-just-got-a-lot-more-granular-139236 http://dl.acm.org/citation.cfm?id=2141571
- http://www.fastcompany.com/1367870/report-nine-scientifically-proven-ways-get-retweeted-twitter
- http://www.sciencedirect.com/science/article/pii/S0167923612001996
- The virtual geographies of social networks: a comparative analysis of Facebook, LinkedIn Zizi Papacharissi New Media & Society, February/March 2009; vol. 11, 1-2: pp. 199-220. http://nms.sagepub.com/content/11/1-2/199.short
- Baresch,B. Knight, L. Harp, D. Yaschur, C. (2011) Friends Who Choose Your News: An analysis of content links on Facebook. presentation at the International Symposium on Online Journalism, Austin, Texas,
- April 2011.
- http://dialnet.unirioja.es/servlet/articulo?codigo=3880702
- http://link.springer.com/chapter/10.1007%2F978-3-642-24704-0_21?LI=true
No comments:
Post a Comment